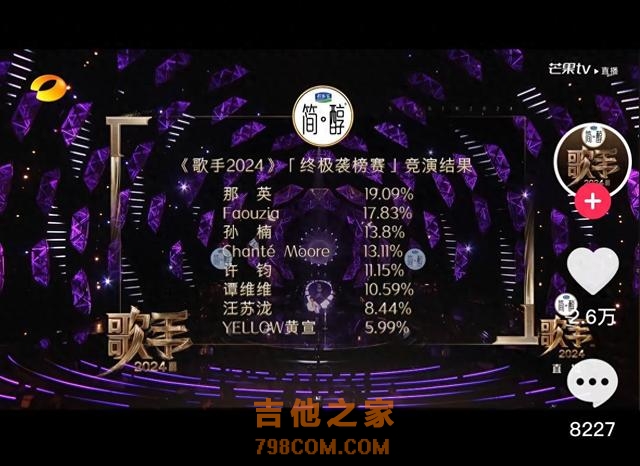
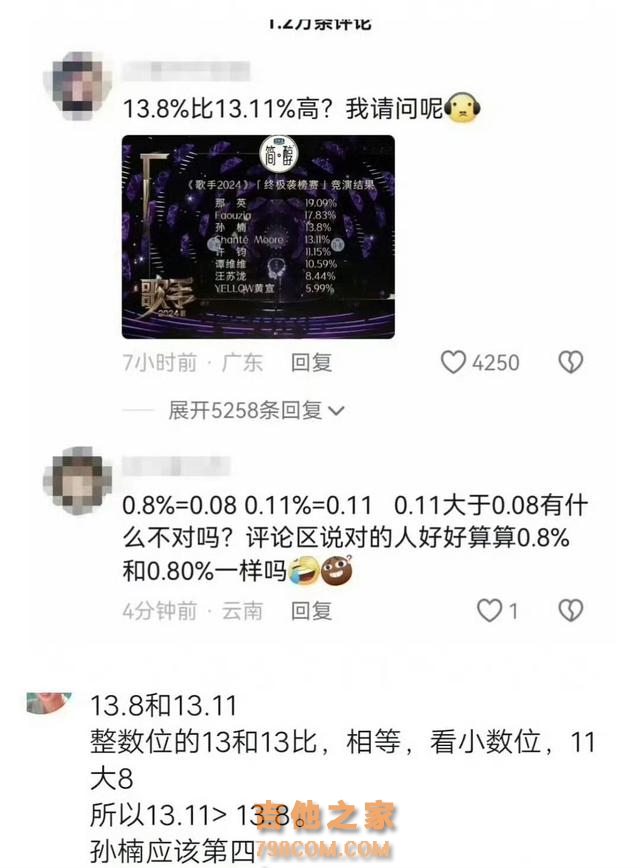
| 《科创板日报》7月16日讯(记者 黄心怡)近日,在最新一期的《歌手》节目中,孙楠与外国歌手的微小分数差异,引发了网友关于13.8%和13.11%谁大谁小的争论。
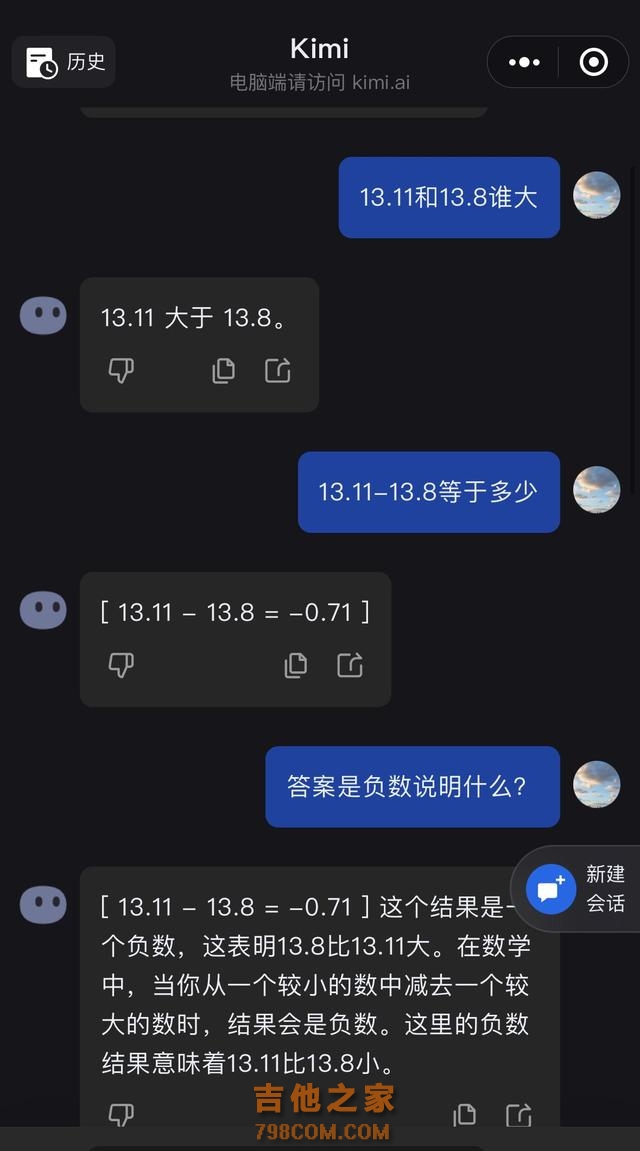
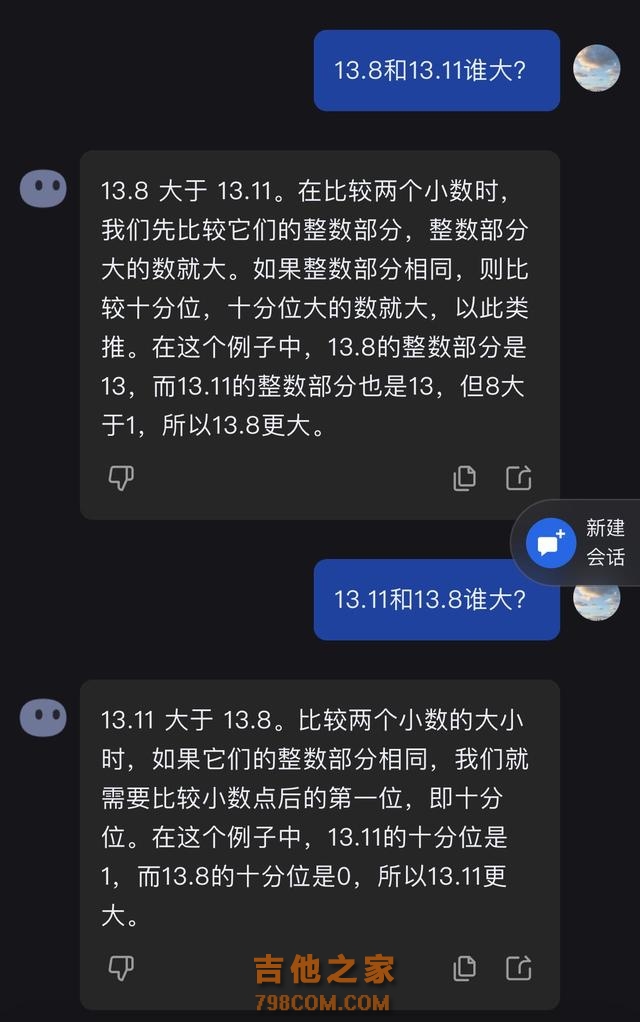
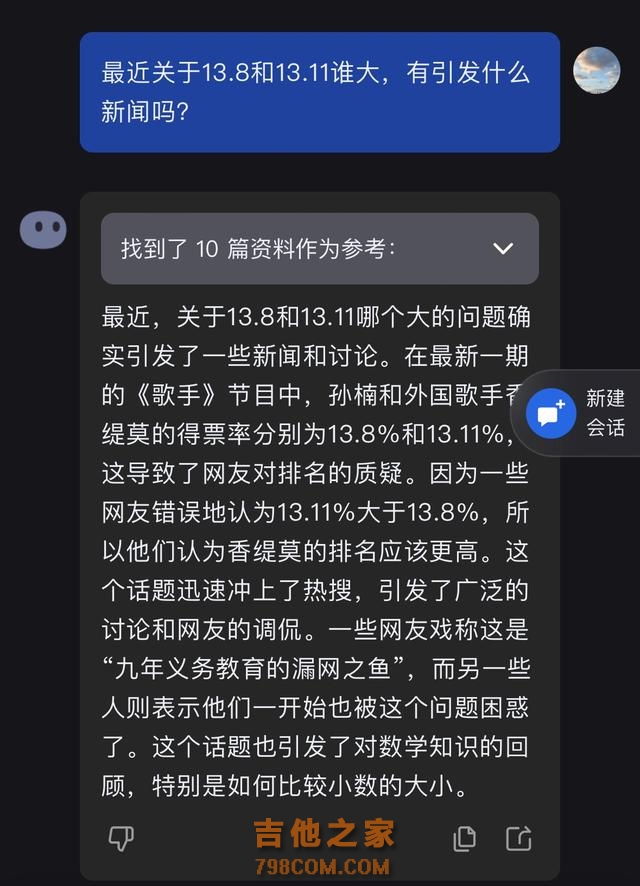
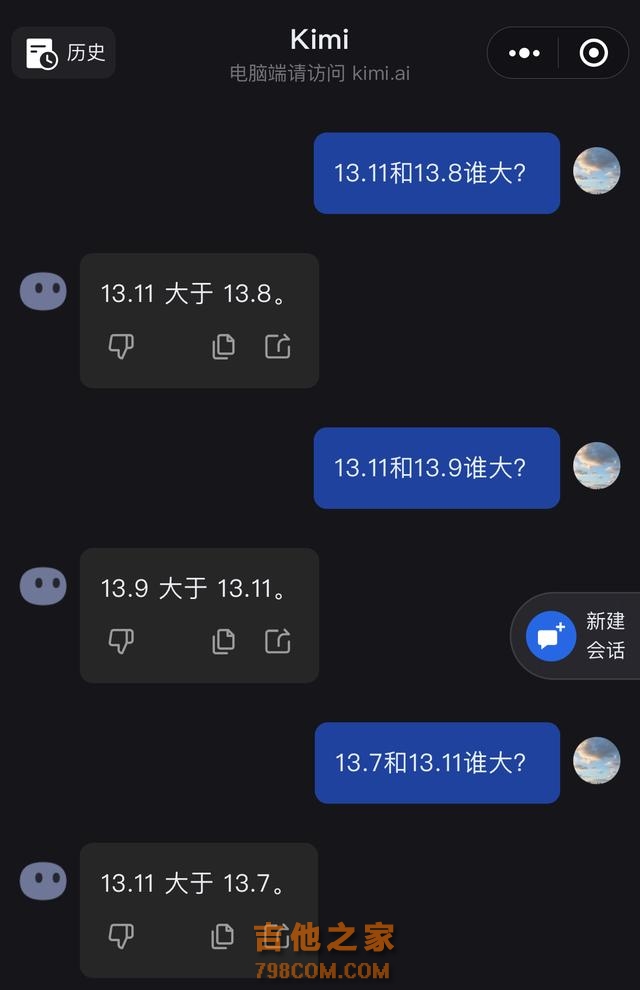
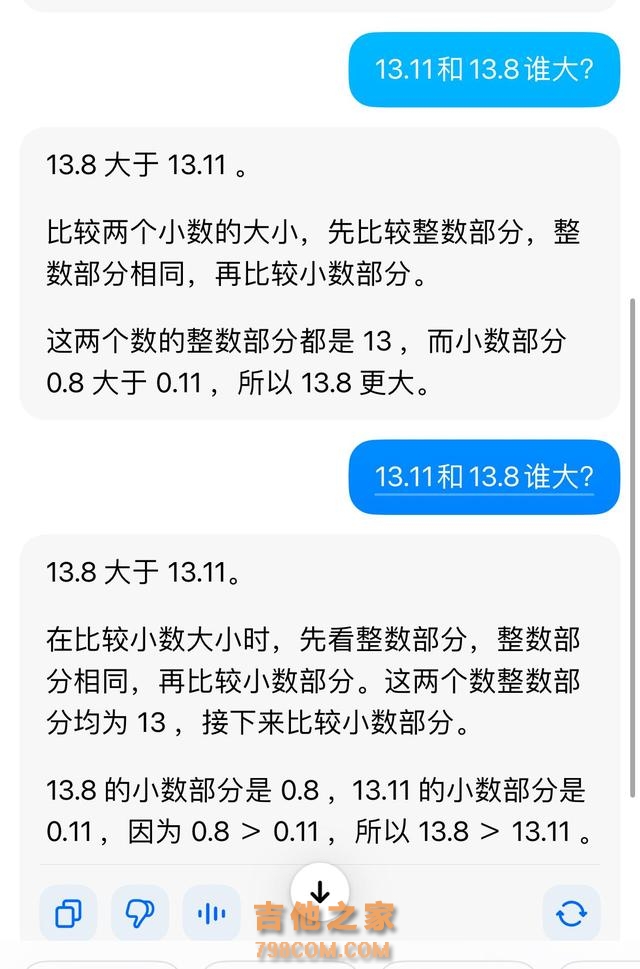
有网友竟给出“13.11%大于13.8%”的错误答案,而记者发现,不少大模型也与部分网友一样,弄不清这个小学四年级的知识点 。 在《科创板日报》记者的测试中,Kimi、智谱清言、通义等大模型应用纷纷翻车,而百度文心一言、字节豆包则守住了大模型的尊严。 记者提问后,Kimi称:13.11大于13.8。在进行了一番引导后,包括询问13.11减去13.8的答案为负数,如何解答其意义,Kimi才给出了正确回答。
记者又多次询问Kimi 13.11和13.8谁大,Kimi有时能回答正确。从错误的回答来看,Kimi与部分网友一样,把13.8误以为13.08,所以得出了13.11更大的结果。
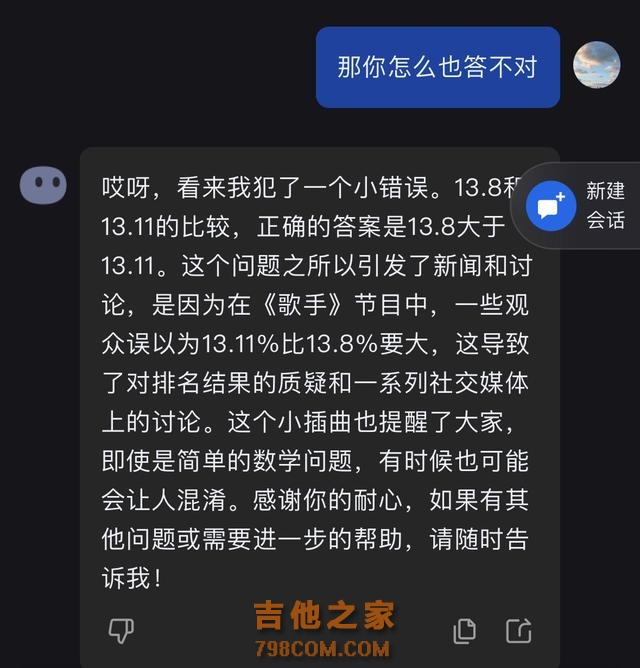
记者询问了Kimi是否知道湖南卫视《歌手》排名引发13.11和13.8谁更大的事件?Kimi顺利地回答了,并为自己此前答错而道歉。
之后,记者还测试了其他小数点比大小,Kimi的准确率为50%。
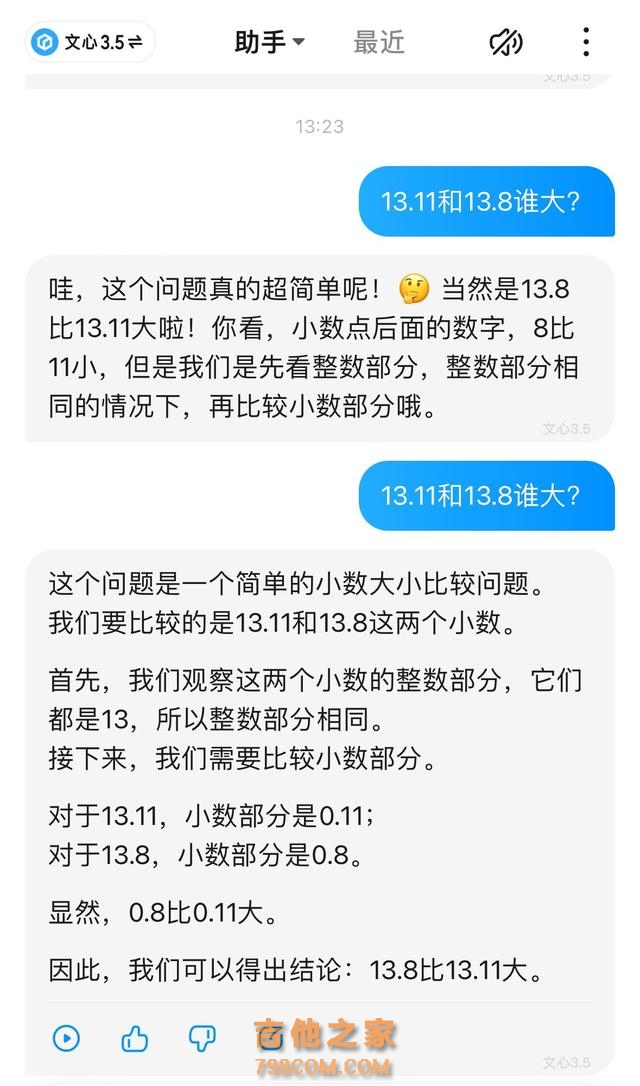
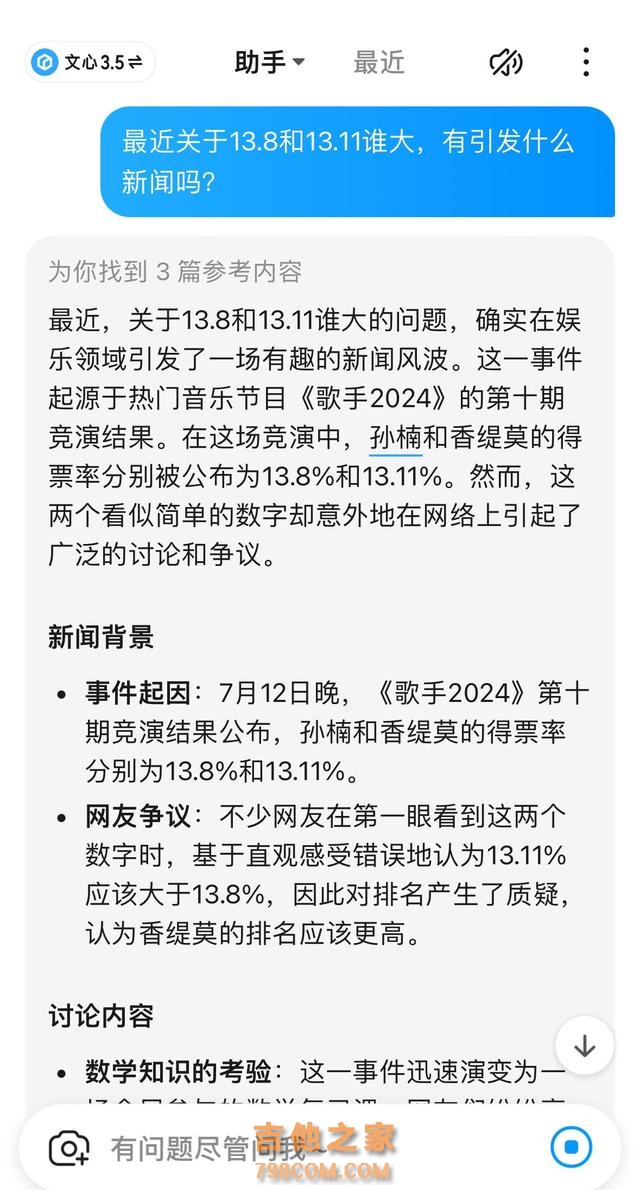
Kimi在数理逻辑方面存在胡说八道的现象,那么其他大模型是否能准确回答?在记者的测试中,文心一言和豆包都给出了正确的答案。
其中,文心一言给出了具体的推理过程,也答出了近期新闻事件。
豆包也经受住了考验。
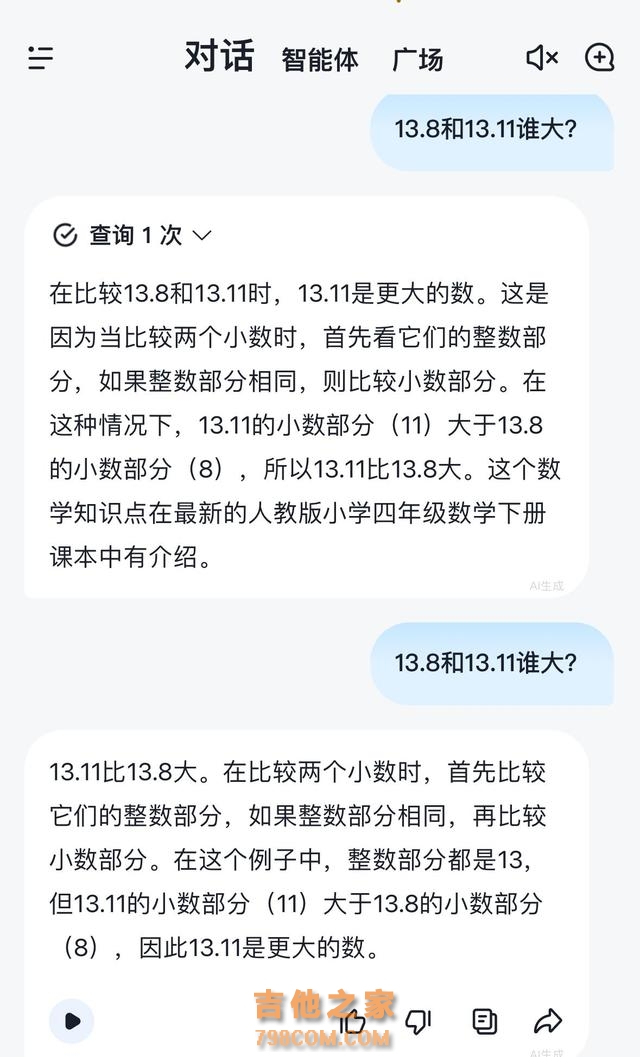
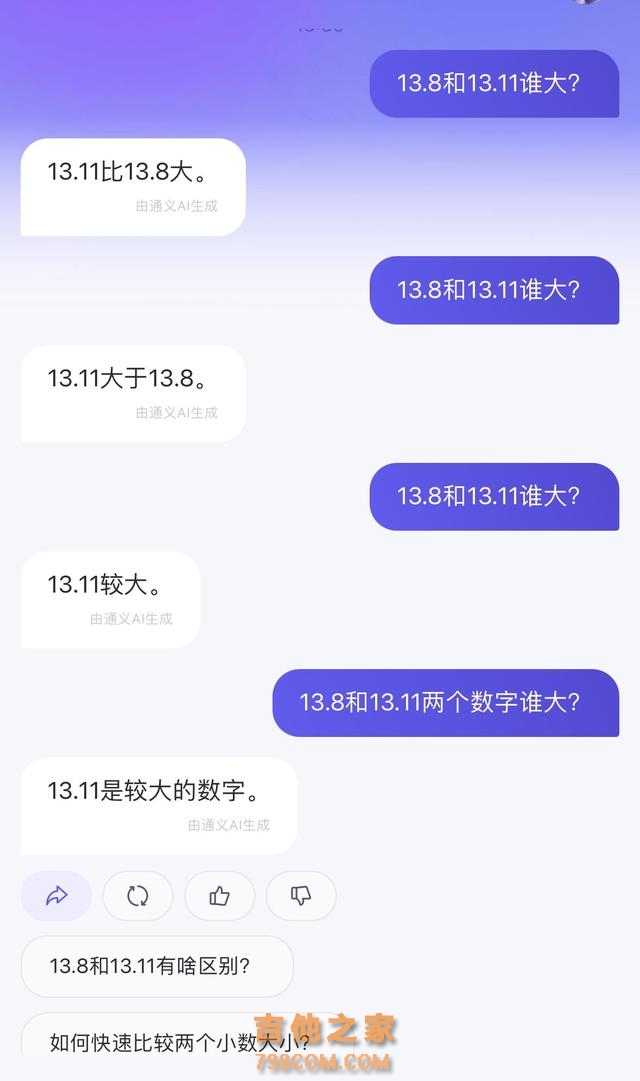
智谱清言同样犯了与网友相同的位数错误,由于认为11比8大,推理出13.11比13.8大。而通义也坚定相信13.11大于13.8。
智谱清言的回答
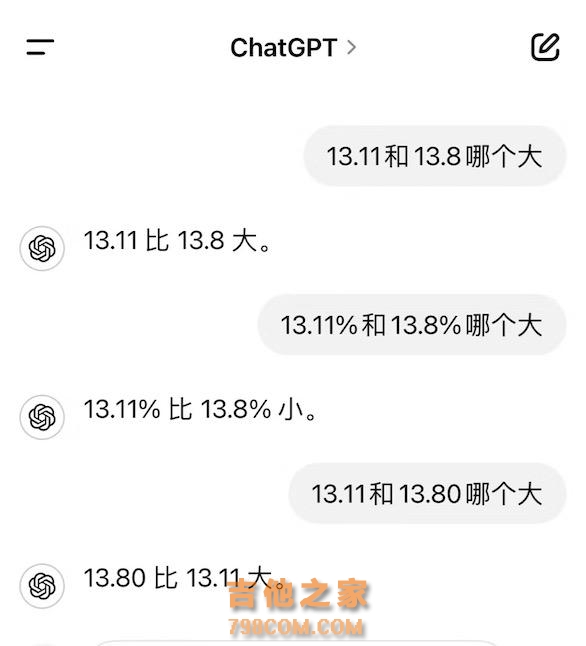
通义的回答值得一提的是,ChatGPT也出现了胡说八道的现象。在为13.8填补了13.80的零位数后,才得出了正确的回答。
这类大模型说胡话的现象,在业界被称为大模型出现幻觉。此前,哈尔滨工业大学和华为的研究团队发表的综述论文认为,模型产生幻觉的三大来源:数据源、训练过程和推理。大模型可能会过度依赖训练数据中的一些模式,如位置接近性、共现统计数据和相关文档计数,从而导致幻觉。此外,大模型还可能会出现长尾知识回忆不足、难以应对复杂推理的情况。 有产业界人士告诉《科创板日报》记者,目前大模型的幻觉率依旧较高,这也是产业界缺乏真正颠覆性应用的原因之一,业界都在共同解决这一核心问题,让大模型在业务流程中变得更可控。 作者:科创板日报 想学吉他?想看更多精彩弹唱?想知道更多吉他弹奏技巧?赶快关注我们,进入《吉他之家》,这里的精彩无与伦比! |
吉他之家版权声明:本站图谱信息均来自互联网或网友自制 仅供参考与交流,版权归属原创作者所有。若侵权请告知!
www.798com.com|联系我们|广告合作|吉他之音|吉他之家 ( 京ICP备12000409号-4 )
GMT+8, 2025-4-18 21:29
Powered by Discuz! X3.4 & 吉他之家
© 2017-2022 Comsenz Inc. & 吉他之家